Unlocking Team Potential - The 7 Levels of Initiative
In our world of engineering management, a big question arises: “What is the best reward for an Engineering Manager?” People have many different answers to this. For me, the best reward is seeing my team grow and do well on their own.
Think about a day at work when your team is full of energy and ideas. They solve problems quickly and work well together. And you? You’re helping them succeed and focusing on the big picture. Your job isn’t just about managing; it’s about leading in a new way.
So, how do we make this happen? How do we unite a group to form a strong team that does better than we ever hoped? The answer is in encouraging initiative.
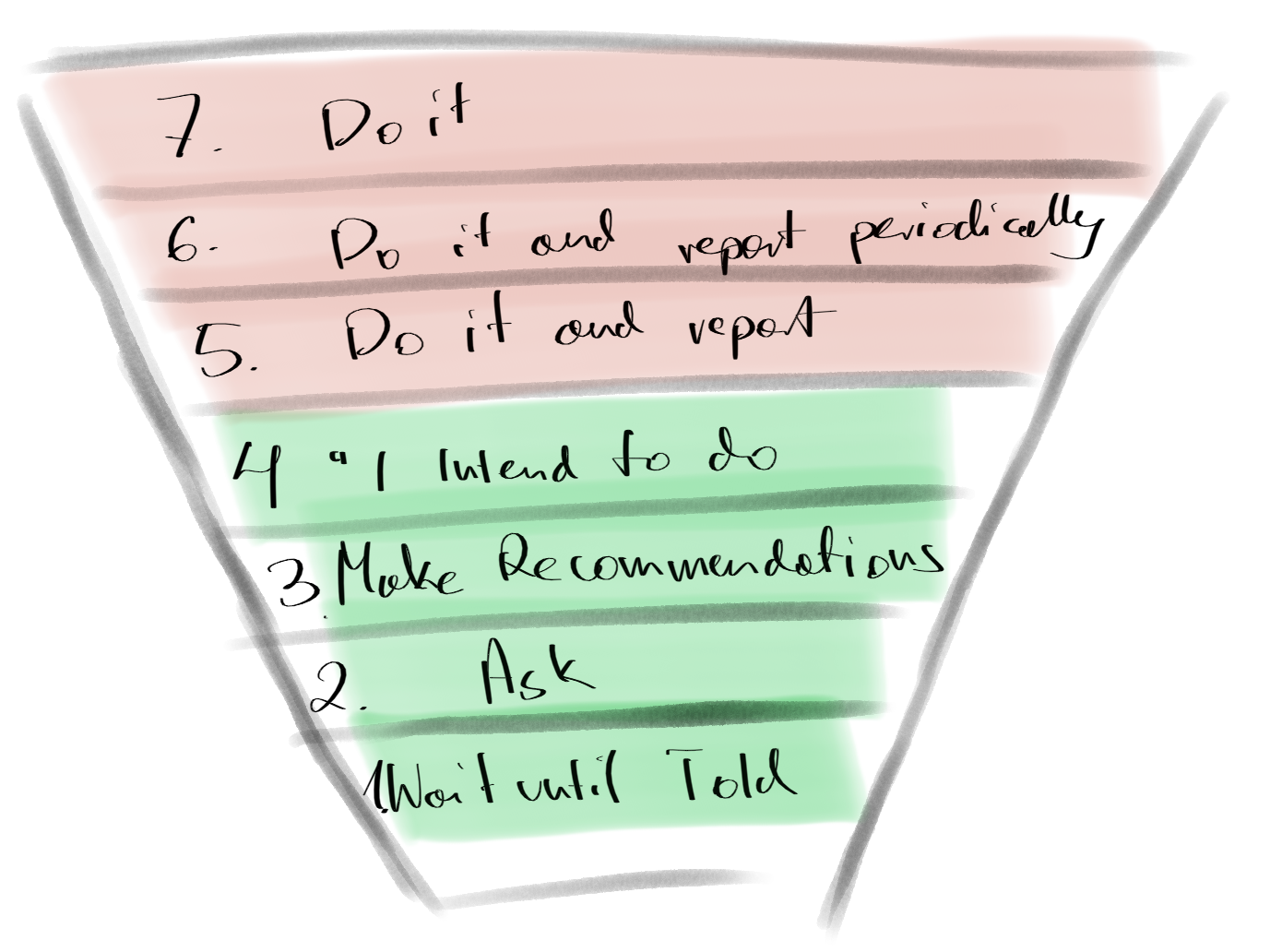
In this blog post, I’ll discuss the 7 Levels of Initiative, an idea from Steven Covey’s research. It’s not just a way to check how well the manager is doing in the team; it’s about helping our teams be their best.